2. 첫 번째 이미지 분류기: k-NN을 사용하여 영상 분류
이미지 분류가 뭔지 알았으니 이번엔 아주 간단한 이미지 분류기를 만들어보겠습니다.

이 알고리즘은 너무 단순해서 실제 "학습"을 전혀 하지 않지만, 여전히 검토해야 할 중요한 알고리즘이기 때문에 향후 신경망이 데이터로부터 어떻게 학습하는지 알 수 있습니다. 마지막으로 다양한 종의 동물을 이미지로 인식하기 위해 k-NN 알고리즘을 적용할 것입니다.
이미지 데이터 세트 작업
이미지 데이터 세트를 작업할 때는 먼저 바이트 단위로 데이터 세트의 전체 크기를 고려해야 합니다. 우리의 데이터 세트는 사용 가능한 RAM에 들어갈 만큼 충분히 큰가요? 큰 matrix나 array를 로드하는 것처럼 데이터 세트를 로드할 수 있나요? 또는 데이터셋이 너무 커서 시스템의 메모리를 초과하여 데이터셋을 부분적으로 로드해야 합니까?
작은 데이터 세트의 경우 메모리 관리에 대한 걱정 없이 메인 메모리에 로드할 수 있지만, 훨씬 큰 데이터 세트의 경우 이미지 분류기를 훈련할 수 있는 방식으로 이미지 로드를 효율적으로 처리할 수 있는 몇 가지 방법을 개발해야 합니다(메모리 부족 없이).
즉, 이미지 분류 알고리즘 작업을 시작하기 전에 항상 데이터 세트 크기를 인식해야 합니다. 이 과정의 나머지 부분에서 살펴보겠지만, 데이터 세트를 구성, 사전 처리 및 로드하는 데 시간을 할애하는 것은 이미지 분류기를 구축하는 데 중요한 요소입니다.
"동물" 데이터 세트 소개
"동물" 데이터 세트는 간단한 예시 데이터 세트로 고급 딥러닝 알고리즘뿐만 아니라 간단한 기계학습을 이용하여 이미지 분류기를 훈련하는 방법을 보여줍니다.
동물 데이터 세트 내의 이미지는 그림 1에서 볼 수 있듯이 개, 고양이 및 팬더의 세 가지 다른 클래스에 속하며 클래스당 1,000개의 예제 이미지가 있습니다. 개와 고양이 이미지는 kaggle Dog에서 샘플링되었습니다. 판다 이미지는 imagenet 데이터 세트에서 샘플링되었습니다.

3,000개의 이미지만 포함하고 있는 Animals 데이터 세트는 쉽게 메인 메모리에서 다룰 수 있습니다. 따라서 메인 메모리에서 다룰 수 없는 큰 데이터를 처리하기 위한 "오버헤드 코드"를 작성할 필요는 없습니다. 무엇보다 딥러닝 모델은 CPU나 GPU에서 이 데이터셋을 빠르게 학습시킬 수 있습니다. 하드웨어 설정에 관계없이 이 데이터셋을 사용하여 머신러닝과 딥러닝의 기초를 다룰 수 있습니다.
이번 블로그의 목표는 k-NN 분류기를 활용하여 이미지를(특징 추출이 수행되지 않음) 개, 고양이, 판다중에 하나로 인식하려고 시도하는 것입니다.
딥 러닝 툴킷의 시작
보시다시피, 우리는 이름이 있는 단일 모듈이 있습니다.
- 이미지(즉, raw pixel)
- 각 이미지와 연관된 클래스 레이블
전처리기는 디스크에서 이미지를 로드하고 가로 세로 비율을 무시하고 고정된 크기로 크기를 조정합니다.
이미지 다운로드
!wget https://pyimagesearch-code-downloads.s3-us-west-2.amazonaws.com/first-image-classifier/first-image-classifier.zip
!unzip -qq first-image-classifier.zip
%cd first-image-classifier이미지를 다운 받습니다. 3000개의 이미지가 폴더별로 개, 고양이, 판다로 구성되어 있습니다.
기본 이미지 전처리기
k-NN, SVM, 심지어 CNN가 같은 기계 학습 알고리즘은 모든 데이터 세트의 이미지가 고정된 크기의 matrix를 가져야 합니다.
이미지의 경우 이미지가 동일한 너비와 높이로 전처리되고 스케일링되어야 함을 의미하죠.
이런 크기조정 및 스케일링을 수행하는 방법에는 아주 아주 많은 방법들이 있는데 차차 알아가보도록 합시다.
정확히 어떤 방법을 사용해야 하는지는 변동 요인의 복잡성에 따라 달라집니다.
우리는 가장 간단한 종횡비를 무시하고 이미지 크기를 조정해보도록 하겠습니다.
class SimplePreprocessor:
def __init__(self, width, height, inter=cv2.INTER_AREA):
# 크기 조정 시 사용되는 대상 너비, 높이 및 보간 방법을 저장
self.width = width
self.height = height
self.inter = inter
def preprocess(self, image):
# 가로 세로 비율을 무시하고 이미지 크기를 고정된 크기로 조정
return cv2.resize(image, (self.width, self.height), interpolation=self.inter)-
width: 크기 조정 후 입력 이미지의 대상 너비.
-
height: 크기 조정 후 입력 영상의 목표 높이.
-
inter: 크기를 조정할 때 사용되는 보간 알고리즘을 제어하는 데 사용되는 옵션 매개 변수입니다.
이 전처리기는 기본적으로 입력 이미지를 받아들이고 고정된 사이즈로 크기를 조정하는 것이 전부입니다. 그러나 이 전처리기의 기법을 사용하면 데이터로더와 결합하여 디스크에서 데이터 세트를 빠르게 로드하고 전처리할 수 있습니다. 즉 파이프라인을 만드는 것인데요. 전처리가 중요할 수록 이 파이프라인을 빛을 발할겁니다.
이미지 로더 작성
class SimpleDatasetLoader:
def __init__(self, preprocessors=None):
# the image preprocessor 저장
self.preprocessors = preprocessors
# preprocessors가 None이면 empty list로 초기화
if self.preprocessors is None:
self.preprocessors = []DatasetLoader를 초기화합니다. preprocessors가 입력되지 않으면 빈 []로 초기화합니다.
def load(self, imagePaths, verbose=-1):
# features와 labels의 리스트 초기화
data = []
labels = []
# loop over the input images
for (i, imagePath) in enumerate(imagePaths):
# 이미지를 로드하고 클래스 레이블을 추출
# 경로의 형식은 다음과 같음
# /path/to/dataset/{class}/{image}.jpg
image = cv2.imread(imagePath)
label = imagePath.split(os.path.sep)[-2]
# preprocessors가 None인지 check
if self.preprocessors is not None:
# 이미지를 전처리기에 각각 적용
for p in self.preprocessors:
image = p.preprocess(image)
# 데이터 목록을 업데이트한 후 레이블을 업데이트함으로써
# 처리된 이미지를 "feature vector"로 취급
data.append(image)
labels.append(label)
# verbose 이미지마다 업데이트를 보여줌
if verbose > 0 and i > 0 and (i + 1) % verbose == 0:
print("[INFO] processed {}/{}".format(i + 1,
len(imagePaths)))
# 데이터와 레이블의 튜플을 반환
return (np.array(data), np.array(labels))
SimpleDatasetLoader.load = load보다시피 데이터셋 로더는 설계가 간단하지만 데이터셋의 모든 이미지에 일괄적으로 프로세서를 쉽게 적용할 수 있습니다. 이 데이터 로더에서 고려해야 할 사항은 모든 이미지가 한 번에 메인 메모리에 들어갈 수 있다고 가정하는 것입니다. 물론 3,000개의 이미지니까 당연히 되겠지만 데이터셋이 더 크다면 우리는 이런 작업까지 고려해야합니다.
k-NN: 단순한 분류기
k-Nearest Neighbor 분류기는 기계학습 알고리즘 중에 가장 간단한 알고리즘입니다. 사실 너무 간단해서 기계학습이라고 하는게 맞나 싶을 정도입니다. 실제로 k-Nearest Neighbor 분류기는 실제로 아무것도 "학습"하지 않습니다. 대신 이 알고리즘은 특징 벡터 사이의 거리(이미지의 원시 RGB 픽셀 intensities)에 매우 의존적입니다.
간단히 말해서 k-NN 알고리즘은 k개의 가장 가까운 예 중에서 가장 일반적인 클래스를 찾아 미지의 데이터 포인트를 분류합니다. k개의 가장 가까운 데이터 포인트의 각 데이터 포인트는 투표를 하며, 그림 2에서 알 수 있듯이 가장 많은 투표 수를 가진 카테고리가 승리합니다.

k-NN 알고리즘이 작동하기 위해서는 내용이 비슷한 이미지는 비슷한 위치에 놓일거라는 가정에서 출발하는데요. 즉 개, 고양이, 판다의 그림을 분류하면 각각 비슷한 공간에 위치할 겁니다. 이 것은 두 고양이 이미지 사이의 거리가 고양이와 강아지 사이의 거리보다 훨씬 작다는 것을 의미합니다.
k-NN 분류기를 적용하려면 먼저 distance-matric이나 similarity function을 선택해야 합니다. 일반적인 선택에는 Euclidean distance(L2- distance)라고 합니다.
(1)
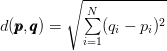
그러나 다른 distance matric(L1-distance)도 사용할 수 있습니다.
(2)

실제로는 데이터에 가장 적합한 L1 distance를 사용할 수 있습니다(최상의 분류 결과를 제공). 하지마 이 블로그에서는 일반적인 거리 측정법인 Euclidean distance를 사용할 것입니다.
A Worked k-NN 예제
이제 k-NN 알고리즘의 원리를 이해해 봅시다. 이제 우리는 k-NN알고리즘이 분류를 만들기 위해 이미지 사이의 거리에 의존한다는 것을 알고 있습니다. 그리고 이러한 거리를 계산하려면 distance matric이 필요하다는것도 이제는 알고 있지요. 그럼 이 것으로 어떻게 분류할까요? 이 질문에 답하기 위해서는 아래 그림3을 보겠습니다. 이 그림에는 개, 고양이, 그리고 팬더의 세가지가 유형의 동물 데이터 세트가 표현되어 있습니다. 그리고 간단하게 털이 있음과 가벼움에 따라 도표화했습니다.

단일 이웃(즉, k = 1)만을 사용하여 분류하려는 "unknown 동물"도 그림에 표현되어 있습니다.이 경우 입력 이미지에 가장 가까운 동물은 개 데이터 포인트 이므로 입력 이미지는 개로 분류되어야 합니다.
이번에는 k = 3을 사용하여 또 다른 " unknown 동물"을 시도해 보겠습니다(그림 4). 상위 3개의 결과에서 고양이 2마리와 팬더 1마리를 발견했습니다. 고양이 카테고리가 가장 많은 득표수를 기록하고 있기 때문에 입력 이미지를 고양이로 분류하겠습니다.
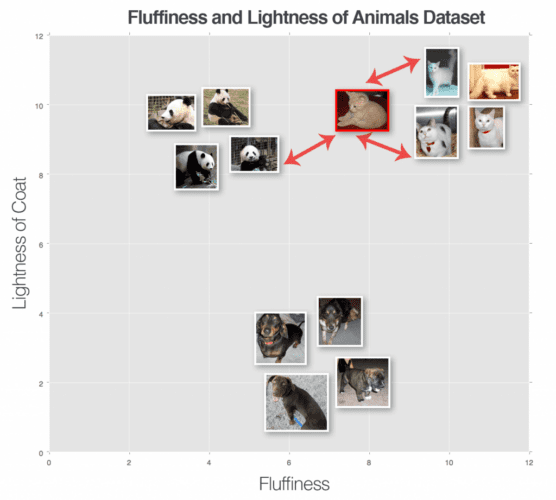
다양한 k 값에 대해 이프로세스를 계속 수행할 수 있지만 이 가장 가까운 데이터포인트로 유추한다는 이 원칙은 계속 유지됩니다. 동점일 경우에는 아무거나 찍습니다.
k-NN 하이퍼파라미터
k-NN 알고리즘을 실행할 때 우려되는 두 가지 명확한 하이퍼파라미터가 있는데요. 첫번째는 k의 값입니다. k가 1이라면 효율성은 얻지만 노이즈 및 이상한 데이터에 너무 취약해지게 됩니다. 그러면 k가 너무 크면 어떻게 될가요? k가 너무 크면 분류 결과가 지나치게 넓어져서 편향이 증가할 위험이 있습니다. 즉 답은 없습니다. 그 어딘가를 찾아가는 과정이 기계학습입니다.
k-NN 구현
이번 블로그의 목표는 동물 데이터 세트의 원시 픽셀에 대한 k-NN 분류기를 훈련하고 알려지지 않은 동물 이미지를 분류하는 데 사용하는 것입니다.
- 1단계 - 데이터셋 수집: Animals 데이터 세트는 개, 고양이 및 팬더 클래스당 각각 1,000개의 이미지와 함께 3,000개의 이미지로 구성됩니다. 각 이미지는 RGB 컬러 공간에 표현됩니다. 각 이미지를 32x32 픽셀로 크기를 조정하여 전처리를 합니다. 3개의 RGB 채널을 고려할 때, 크기가 조정된 이미지 치수는 데이터 세트의 각 이미지가 32×32×3 = 3,072 정수로 표현된다는 것을 의미합니다.
- 단계 #2 — 데이터 세트 분할: 이 간단한 예를 위해 데이터를 두 번 분할하여 사용합니다. 하나는 훈련을 위해, 다른 하나는 테스트를 위해 분할합니다.
- 단계 #3 — 분류기 훈련: k-NN 분류기는 훈련 세트의 이미지의 픽셀에 대해 훈련을 받을 것입니다.
- 4단계 — 평가: k-NN 분류기가 교육되면 테스트 세트에서 성능을 평가할 수 있습니다.
# import the necessary packages
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imutils import paths
import numpy as np
import argparse
import cv2
import os
# ap = argparse.ArgumentParser()
# ap.add_argument("-d", "--dataset", required=True,
# help="path to input dataset")
# ap.add_argument("-k", "--neighbors", type=int, default=1,
# help="# of nearest neighbors for classification")
# ap.add_argument("-j", "--jobs", type=int, default=-1,
# help="# of jobs for k-NN distance (-1 uses all available cores)")
# args = vars(ap.parse_args())
args = {
"dataset": "dataset/animals",
"neighbors": 1,
"jobs": -1
}- KNeighborsClassifier는 scikit-learn 라이브러리에서 제공하는 k-NN 알고리즘의 구현입니다.
- LabelEncoder는 문자열로 표시되는 레이블을 클래스 레이블당 하나의 고유 정수가 있는 정수로 변환해주는 유틸리티입니다.
- train_test_split은 훈련 및 테스트 분할을 만드는 데 사용됩니다.
- classification_report은 분류기의 성능을 평가하고 콘솔에 잘 포맷된 결과 표를 인쇄하는 데 사용됩니다.
-
--dataset : 디스크의 입력 이미지 데이터 세트가 있는 경로입니다.
-
--neighbors : k-NN 알고리즘을 사용할 때 적용할 이웃 수 k(선택사항)입니다.
-
--jobs: 입력 데이터 지점과 교육 세트 사이의 거리를 계산할 때 실행할 동시 작업 수(선택 사항). 의 값.(-1 프로세서에서 사용 가능한 모든 코어를 사용합니다.)
이제 데이터 세트에 있는 이미지의 파일 경로를 로드하고 전처리를 수행합니다.
# 이미지 목록 로드
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
# 이미지 전처리기를 초기화하고 디스크에서 데이터 세트를 로드한 다음 데이터 매트릭스를 재구성
sp = SimplePreprocessor(32, 32)
sdl = SimpleDatasetLoader(preprocessors=[sp])
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.reshape((data.shape[0], 3072))
# 이미지의 메모리 사용량에 대한 일부 정보를 표시
print("[INFO] features matrix: {:.1f}MB".format(
data.nbytes / (1024 * 1024.0)))→ Launch Jupyter Notebook on Google Colab
디스크에서 이미지를 로드한 후, data NumPy 배열에는 (3000, 32, 32, 3) 크기의 matrix가 만들어 질겁니다.
데이터 세트 3,000개에 32x32픽셀의 3개의 채널(RGB)가 있다는 뜻입니다.
그러나 k-NN 알고리즘을 적용하려면 이미지를 3D 표현에서 1차원으로 변형해야합니다.
# 라벨을 정수로 encode
le = LabelEncoder()
labels = le.fit_transform(labels)
# 데이터의 75%를 훈련용으로, 나머지 25%를 테스트용으로 사용하여 데이터를 훈련 및 테스트로 분할
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.25, random_state=42)
마지막으로 k-NN 분류기를 생성하고 이를 평가할 수 있습니다(이미지 분류 파이프라인의 단계 #3 및 #4).
# train and evaluate a k-NN classifier
print("[INFO] evaluating k-NN classifier...")
model = KNeighborsClassifier(n_neighbors=args["neighbors"], n_jobs=args["jobs"])
model.fit(trainX, trainY)
print(classification_report(testY, model.predict(testX), target_names=le.classes_))
# [INFO] evaluating k-NN classifier...
# precision recall f1-score support
#
# cats 0.37 0.52 0.44 239
# dogs 0.39 0.46 0.42 262
# panda 0.85 0.36 0.50 249
#
# accuracy 0.45 750
# macro avg 0.54 0.45 0.45 750
# weighted avg 0.54 0.45 0.45 750
분류기를 평가해 보면, 우리는 54%의 정확도를 얻었음을 알 수 있습니다. 무작위로 정답을 추측할 확률이 1/3임을 감안할 때, 이 정확도는 "학습"을 전혀 하지 않는 분류기에 나쁘지 않습니다.
그러나 각 클래스 레이블에 대한 정확도를 검사하는 것은 흥미롭습니다. "팬더" 분류는 대부분의 시간의 85%를 정확하게 분류했는데, 이는 팬더가 대부분 흑백이므로 이러한 이미지가 3,072차원 공간에 더 가까이 놓여 있기 때문일 수 있습니다.
개와 고양이는 각각 39%와 37%로 상당히 낮은 분류 정확도를 얻습니다. 이러한 결과는 개와 고양이가 털 코트의 매우 유사한 색조를 가질 수 있고 그들의 코트 색깔을 구별하는 데 사용할 수 없기 때문이라고 할 수 있습니다. 배경 또한 k-NN 알고리즘을 "혼란스럽게" 만들 수도 있습니다. 이들 종 간의 구별되는 패턴을 학습할 수 없기 때문입니다. 이러한 혼란은 k-NN 알고리즘의 주요 단점 중 하나로, 단순하지만 데이터로부터 학습할 수 없다는 것입니다.